Анализ частотности поисковых запросов. Частотность поисковых запросов
Здравствуйте, уважаемые читатели блога сайт! На очереди у нас с вами онлайн инструмент, причем весьма качественный и во многом не уступающий программным аналогам, который нам предлагает многофункциональный сервис Topvisor.ru (прошлая публикация была посвящена полному ), являющийся на данный момент, пожалуй, самым прогрессирующим на просторах рунета.
С помощью данного инструмента можно собрать семантическое ядро для (в рамках его поискового продвижения), а также подобрать ключевые слова для кампании по контекстной рекламе. Попробуем оценить его возможности, а также то, насколько удобно и просто работать в интерфейсе, где все продумано до мелочей.
Отдельные опции этого процесса в Топвизоре являются платными, но за сравнительно небольшие деньги вы получаете очень качественный результат. Особенно, если учесть, что тут реализована возможность собрать именно полноценное , не только определив цену за клик и частотность запросов , но и сразу сгруппировав ключевые слова в нем под раскрутку разделов или даже отдельных статей вашего нового или уже имеющегося сайта.
Поиск ключевых слов в Яндексе, Google и др. источниках
Для начала вступительное пояснение. В процессе повествования в этой и других публикациях я буду использовать на равнозначной основе (отмечаю это для того, чтобы не возникало путаницы), так как они имеют единый общий смысл (на основе первых создаются вторые, которые затем составляют семядро) и отличаются лишь в единственном нюансе, а именно в том, что .
Ну а теперь переходим непосредственно к практике, а именно, к созданию СЯ. Надо сказать, что Topvisor предоставляет для этого абсолютно все инструменты и помогает подобрать ключевые слова для сайта автоматически в онлайн режиме. Вначале из верхнего меню выбираем нужный нам проект и переходим во вкладку «Ядро» , где расположен большой знак «+»:

После нажатия на этот плюс образуется новая группа (блок), которой можно присвоить нужное название и в состав которой можно различными способами добавлять ключевики. Но о такой возможности мы поговорим чуть позже, так сказать, в процессе.
Напомню, что можно импортировать необходимые запросы (если они у вас уже имеются) для семантического ядра, которое вы будете составлять для уже действующего либо будущего вебпроекта. С этой целью достаточно нажать на соответствующую кнопку:

Появится отдельное окошко, в котором можно ввести ключевики двумя способами: просто вписать их по одному в строку вручную (или и вставить) либо скачать файл в формате CSV или TXT:

Возможно сразу создать группу (введя в соответствующую графу ее название) для импорта слов и словосочетаний. В ином случае система распределит их по автоматически созданным группам, которые в будущем можно распределить по папкам для упрощения систематизации.
Основной поиск ключевиков, конечно же, происходит на основе . Для его активации следует нажать на кнопку подбора ключевых слов (кроме баз Yandex и Google в Топвизоре существует возможность выудить запросы из панели вебмастеров Mail.ru и Bing):

Одной из сторон функционала Топвизора является автоматизация сбора запросов с , который, к сожалению, можно использовать только в ручном режиме (начинающим полезно будет перейти по данной только что ссылке и ознакомиться с нюансами).
При создании либо расширении СЯ уже существующего сайта учитывайте региональность. Для информационного, ну или любого другого сайта, не являющегося геозависимым, можно указать широкий регион (например, «Россия») для учета языковых предпочтений. Для коммерческого или любого другого ) проекта нужно указать более узкий регион (Москва, Тверь и т.д.). Это поможет привлечь больше целевых посетителей и стабилизировать бюджет.
При этом система собирает вложенные запросы из статистики Яндекса (которая как раз выдается посредством Вордстата через Я.Директ ) на основе базовых фраз, иначе говоря, масок (их может быть одна или несколько), которые и следует ввести в имеющееся поле. Если вы желаете расширить список найденных ключей, то отметьте галочкой опцию «С этим искали».
Тем, кто еще не ознакомился с мануалом о сервисе подбора ключевых слов от Яндекса, скажу (а остальным напомню), что в левой части интерфейса Вордстата в результате поиска находятся словосочетания, которые являются производными от введенной вами фразы или слова (то есть, вложенными запросами). В случае, если ключ достаточно популярен, может образоваться правая колонка, в которой будут представлены так называемые ассоциативные запросы, вводимые пользователями в течении одной поисковой сессии:

Как было отмечено, система находит ключевые слова также из статистики Google Adwords (напомню, что существует , который более сложен по сравнению с Вордстатом), Webmaster Mail , Webmaster Bing , если, конечно, вы пожелаете задействовать эти источники, заполнив чекбоксы (проставив галочки) напротив соответствующих опций (посмотрите на пред-предыдущий скриншот).
Смотрим далее настройки сбора ключевых слов. Чуть ниже выбора источников можно ввести минус-фразы , они могут быть и отдельными словами (это по сути ). Данные слова или словосочетания будут исключены из списка запросов, так как по логике не подходят для данного семантического ядра (опять же изучите второй скриншот вверх отсюда).
Скажем, ежели вы имеете некоммерческий информационный ресурс, то минус-фразами вполне могут быть следующие: «купить», «цена», «стоимость», «заказать». И наоборот, для e-commerce безболезненно можно отфильтровать слова «бесплатный», «самостоятельно» и т.п. (думаю, суть вы поняли). Для активации этой функции отметьте ее галочкой.
Ну и для удобства можно собрать все данные в одну группу (иногда это удобно), для этого также заполните соответствующий чекбокс. Затем можно нажать на кнопку «Начать» для активации операции. В ходе парсинга ключевых слов система автоматически образует несколько блоков для каждой введенной маски, где будет происходить имитация известных игр "Тетрис" или "Змейка". Процесс займет всего лишь несколько минут и по его окончании станет видимым результат:

Здесь представлены перечни основных и сопутствующих («с этим искали») запросов (из левой и правой колонки Вордстат). Для некоторых уже показана частотность в Яндексе (справа) и цена клика рекламы в Директе (слева). На скриншоте выше эти данные обведены красной рамкой.
Вообще для получения подобных данных в полном объеме требуется активировать отдельную операцию, которую мы обязательно рассмотрим чуть ниже. Однако, Топвизор предоставляет сразу часть информации, которая ранее уже была оплачена другими пользователями этого сервиса.
Ну и добиваем сбор КС из поисковых подсказок . Топвизор предлагает искать их из целых семи источников (нужные отмечаете галочками), при этом для отсева ненужных данных и упрощения дальнейшей работы желательно указать регион для некоторых из них. Далее выбираете глубину (1, 2, 3) и метод поиска (эти настройки надо выставлять разумно, чтобы не израсходовать лишние средства, поскольку операция то платная):

Постараюсь облегчить вам выбор и помочь понять суть опций. Что касается методов подбора подсказок , то лучше всего они описаны на этой странице хелпа , где с помощью гифок все четко разъяснено (подводите курсор к каждой из картинок и нажимаете на кнопку запуска).
Наверное, стоит также прояснить, что вообще представляют из себя эти самые подсказки и их уровни. Дело в том, что когда пользователь начинает вводить запрос в поисковое поле, система предлагает ниже поля ввода сразу несколько вариантов, связанных с вводимым словосочетанием, которые наиболее часто использовались другими юзерами, чтобы ускорить процесс. Рассмотрим все это на примере Яндекса. Откроем страницу поиска и введем запрос из нашего примера:

Появившиеся ниже словосочетания являются подсказками первого уровня . Ежели взять из этого списка одну из фраз, то при ее вводе появится уже перечень подсказок второго уровня :

И так далее. Таких уровней может быть очень много. Естественно, не все ключи имеют подобные "хвосты", многое зависит от популярности вводимой фразы. Topvisor предлагает три уровня поисковых подсказок, что вполне может обогатить состав семантического ядра. Но продолжим. После парсинга всех возможных источников будут сформированы отдельные группы ключевиков.

Самое замечательное в том, что повторяющиеся слова и словосочетания, полученные из разных мест, система отсеивает автоматически, поэтому исключена любая путаница. Чтобы дополнить список ключевых слов для семантического ядра, Топвизор предлагает еще одну возможность для тех, кто уже имеет сайт со страницами, оптимизированными под определенные ключевики, по которым существуют переходы реальных пользователей.
С этой целью выбираем опцию «Магнит» , которая инициирует сбор статистических данных из , Google Analytics и (о том, как интегрировать данные из этих сервисов, написано в статье с обзором всего функционала Топвизора, на которую вы можете перейти по ссылке в самом начале публикации):

После завершения процесса образуется новый перечень ключей, которые будут соответствовать уже существующим статьям с реальными визитами и к которым можно будет добавить еще не учтенные словосочетания, которые найдутся с помощью Топвизора.
Массовая проверка частотности запросов онлайн и определение цены клика в Директе и Adwords
Итак, мы получили целую кучу всевозможных фраз для ядра из различных источников с помощью функции подбора ключевых слов онлайн. Теперь настало время систематизировать это богатство, удалив бесперспективные фразы, в том числе пустышки, по которым продвигать веб-странички будет нерентабельно и затратно. С этой целью для начала необходимо проверить частотность запросов в Яндексе (ну и до кучи в Гугле, это тоже может оказаться полезным). Жмем на соответствующую кнопку во вкладке «Ядро» и выбираем источник:

Здесь для получения необходимой нам информации требуется указать тип соответствия . Для Яндекса, например, это не что иное как автоматическое применение системой , которые помогают получить корректную частотность и исключить пустышки.
Решение, какие операторы использовать, зависит во многом от типа сайта и его тематики. Для создания семядра стандартного информационного ресурса типа данного блога, часто достаточно двух, а именно кавычек («""»), в которые заключается слово или фраза, и восклицательного знака («!»), проставляемого перед каждым словом в словосочетании.

А вот для коммерческих ресурсов любых видов, а тем более при создании рекламной кампании, скорее всего, потребуется задействовать все возможные операторы (не зря же они разработаны).
Для получения корректной частотности запросов в Гугле используется единственный оператор [Частота], которого вполне хватает с учетом алгоритмов работы его статистического сервиса.
Перед сбором частотности важно еще узнать стоимость клика . Рекламодателям и владельцам коммерческих проектов без данной операции, как вы понимаете, не обойтись, но и при создании семядра для информационного сайта подобная информация также может быть полезной, если, конечно, вы скрупулезно учитываете даже малейшие нюансы при продвижении своего детища.
В Яндекс Директ существует два вида контекстной рекламы в зависимости от места расположения объявлений на веб-странице результатов поиска: «спецразмещение» и «гарантированные показы» . Попытаемся проанализировать вкратце, что они означают.

Этот тариф подразумевает нахождение рекламы вверху страницы, на которую отведено 4 места, а в самом верху будет расположено объявление, соответствующее первому месту (в Топвизоре это «1 Спецразмещение»). Естественно, за размещение на таких выгодных позициях рекламодатель должен выложить кругленькую сумму и цена за клик будет достаточно высокой. В общем случае работает правило, при котором выше расположенные рекламные объявления стоят дороже (это и понятно, ведь чем выше находится рекламный блок, тем чаще по нему кликают пользователи).
На выше расположенном скриншоте по данному запросу заполнены все возможные 4 места, но объявлений может быть и меньше, все зависит от уровня конкуренции (естественно, при низком ее уровне и стоимость объявлений будет небольшая). Кстати, Topvisor при желании предоставит вам расценки по всем позициям спецразмещения. Это особенно важно для полновесного анализа частотности запросов при составлении рекламной кампании.
Как я уже сказал, для отбора семантики сайтов, продвигаемых методом SEO (для коммерческих в большей степени, для некоммерческих — в меньшей), аналитические данные по стоимости кликов могут также дать весьма существенную пользу.
Представьте, что вы продвигаете страницу под конкретный запрос, где цена клика весьма высока. Даже если документ попадет в ТОП-10 выдачи, далеко не факт, что вебсайт получит достаточное количество посетителей, поскольку по этому же ключевику присутствует целый блок рекламных объявлений, которые расположены выше списка результатов органической выдачи. Тем более, что в недавнем прошлом Яндекс отменил нумерацию позиций и тем самым сильно затруднил пользователям восприятие границы между обычным поиском и рекламой. Это важно учитывать.

"Гарантия", несмотря вроде бы невыгодное место расположения рекламы, в конечном счете может оказаться довольно эффективным способом вложения средств для рекламодателей. Однако, здесь многое зависит от тематики и некоторых других факторов. Поэтому в каждом конкретном случае необходимо чрезвычайно тщательно анализировать ситуацию, иначе неизбежен слив бюджета.
Что касается сборки СЯ для некоммерческих вебсайтов, то отмечу следующее. Многие вебмастера участвуют в и ставят на своем ресурсе , что является одним из , приносящим порой немалый доход.
Но контекст на странице, естественно, завязан на ее содержании. А значит, на тех ключах из семантического ядра, под которые заточена публикация. Поэтому после получения всех данных по частотности запросов и стоимости кликов соответствующих рекламных блоков можно отсеять те ключи, которые будут слишком конкурентными в сравнении с вашими возможностями, а значит, недостаточно эффективными в плане привлечения достаточной аудитории на сайт.
Теперь, после всех выше предоставленных предварительных выкладок ваша теоретическая база достаточно объемная для того, чтобы корректно задать нужные источники сбора запросов и тип частоты. При этом имейте ввиду, что если вы для Яндекса отметите галочкой «"!Частота" + стоимость», то получите цену за клик по всем видам размещения.
Есть еще две опции, которые можно отметить галочками: «Пропустить проверенную частоту» (тем самым не надо платить лишние деньги за уже полученные ранее результаты) и «Проверить устаревшую частоту» , с помощью которой по ходу пьесы обновляем данные (см. четвертый скриншот отсюда вверх). После выполнения всех настроек можно запускать процесс (кнопка «Проверить частоту»), ход которого обозначен бегущими по поверхности кнопки полосами:

По окончании сего действа Топвизор попросит вас обновить страницу, после чего можете лицезреть результирующую картинку:

Теперь для отображения нужных данных из менюшек в верхней панели вы можете выбрать источник (поисковые системы Yandex, Google или go.Mail), вид размещения рекламы от Яндекс Директ («спецразмещение», «гарантированные показы») и тип соответствия, то есть частотность для выбранных вами операторов ("Частота", "!Частота" и т.д.).
");">
Функция фильтрации в интерфейсе Топвизора
Итак, мы создали с помощью системы несколько блоков необходимых нам словосочетаний для ядра. В ходе сбора семантики посредством операторов (включая минус-фразы) уже отсеялась большая часть "мусора", включая "пустышки".
Дальнейшие действия по фильтрации зависят от того, какого типа и тематики сайт вы имеете. Многие небольшие коммерческие ресурсы (уж только что созданные точно) продвигаются не только под низкочастотные, но и сверх-низкочастотные запросы, поэтому в этом случае, возможно, стоит сохранить все собранные на этот момент ключи.
А вот, например, для информационного проекта, даже свежеиспеченного, ключевики с очень маленькой частотностью (например, менее 10) порой просто нерентабельны. Никакого сколь-нибудь заметного трафика они не дадут, а драгоценное время отнимут. Поэтому жмем кнопку фильтрации и выбираем ее вид «по частоте» из выпадающего меню:

Обратите внимание, что при таких настройках запросы с установленной минимальной частотой не будут удалены (это можно сделать в любое время), а упадут в отдельную группу, предложенную Топвизором (кстати, ее название по умолчанию можно изменить). Возможно, впоследствии кое-какие из этих ключей могут пригодиться (например, возрастет частотность, что иногда случается).
Кстати, существует возможность выбрать поисковые запросы не только с частотой ниже какого-то значения, но и выше (знаки «больше» и «меньше» также выбираются из выпадающего меню). Вот какие еще какие возможности фильтрации по частоте предлагает система:

Чего тут только нет! Вы в силах отфильтровать все запросы во всех группах по частотности, сами группы по частоте, алфавиту, дате добавления, применить инструмент «Найти и заменить», даже сменить протокол ссылок на целевые страницы и т.п. В общем, есть все для комфортной работы.
Кластеризация запросов онлайн
Вот мы и подошли к решающему этапу, который, пожалуй, является основным при составлении семантического ядра вебсайта. Именно эта функция системы позволяет произвести группировку ключевых слов таким образом, чтобы обеспечить наиболее эффективную структуру вашего веб-проекта для его дальнейшего продвижения.
Кластеризация ядра дает возможность распределить все запросы так, чтобы они составляли готовые списки не только для каждого раздела сайта, но и для любой из веб-страниц. Если вы запланируете написать статью на определенную тему, то список ключевых слов для нее будет уже практически готов. Конгениально, не правда ли?
Для чего это вообще нужно? Дело в том, что алгоритмы поисковиков ранжируют веб-странички, продвигаемые сразу по нескольким запросам одной тематики, но не все они могут обеспечить высокие позиции в выдаче, поскольку по некоторым факторам они несовместимы друг с другом (скажем, по информационным и коммерческим ПЗ никак нельзя продвинуть одну страницу).
Как же узнать, какие ключевики, соответствующие конкретным запросам, обеспечат высокие позиции одной и той же страницы сайта? Вот именно в этом и поможет нам Топвизор.
Прежде чем продолжить, отмечу, что Topvisor предлагает различные виды группировок (при этом и «по целевым URL» являются бесплатными, возможно, именно какой-то из них для вас окажется достаточно):

Но самый крутой метод, как всегда, платный (кластеризация по ТОП-10 ), и от этого не уйти, если, конечно, вы собираетесь достигнуть настоящего успеха в раскрутке проекта.
Но на чем основан алгоритм системы при осуществлении такого вида группировки? Технически это происходит так. Сервис исследует содержание ТОП-10 соответствующей поисковой машины и находит совпадения групп ПЗ для страниц сайтов, которые находятся на верхних позициях.
Далее. Ежели таких совпадений несколько, то ключевики объединяются в блоки, названия которых определяет самый высокий по частотности запрос. Те словосочетания, по которым не найдено ни одного совпадения, попадают в отдельный список «Запросы без связей».
Все это довольно логично. Ведь если в ТОП попали страницы сайтов с определенным набором ключей, значит, поисковые системы благосклонно к этому относятся, и есть смысл последовать их примеру. В общем, группировка — это операция, которая придает законченность семантическому ядру. Вот так активируется процесс кластеризации:

Прежде всего, надо указать поисковую систему, язык и регион (широкий для информационного ресурса, например, «Россия» либо более конкретизированный для коммерческого, скажем, «Новгород»). Также можно попросить систему отправить на почту отчет о кластеризации, отметив соответствующую опцию галочкой (наверное, это нужно в тех случаях, когда семантическое ядро содержит огромное количество ключевиков и процесс займет много времени).
Обратите внимание, что существует возможность выбора степени группировки . Эта величина определяется количеством документов с одинаковым набором запросов, по которым будет производится кластеризация. Вероятность того, что будут совпадения, скажем, по двум страницам, попавшим на первые места, гораздо выше, чем по восьми-девяти.
Таким образом, чем меньше степень, тем более объемными по содержанию будут блоки и их количество будет меньше. Однако, совпадения по одному-двум запросам тоже недостаточно, поэтому по умолчанию Топвизор предлагает степень группировки «3». Вы вольны выбрать для себя любую степень, только обязательно ниже приведенные рассуждения.
По логике для информационных ресурсов нужно выбирать меньшую степень, поскольку страницы там обычно затачиваются сразу под большое количество ключей, а для небольших коммерческих сайтов (например, интернет-магазина), отдельные странички которых продвигаются максимум по двум-трем запросам, лучше применить большую степень. Но, как говорится, возможны варианты.
Не менее важной настройкой перед запуском группировки является метод кластеризации (soft, moderate, hard). Чтобы решить, какой из них выбрать, изучите эту вебстраницу помощи , где в лаконичной форме все наглядно продемонстрировано и понятно объяснено.
После того, как вы сделали все настройки, жмите на кнопку «Начать» . Процесс кластеризации длится недолго, для тысячи ключей, к примеру, он не занимает более 5 минут. После окончания операции распределения ключевых слов и фраз итоговые группы будут выглядеть примерно так:

В результате получена по сути готовая структура для нового сайта, где для каждой веб-страницы уже есть список ключевых слов. Ежели у вас действующий проект, то на основании результатов кластеризации вы сможете внести нужные изменения и дополнения в имеющиеся странички и/или добавить необходимые ключи в текстовое содержание вновь созданных страниц.
В качестве дополнительного материала обязательно посмотрите видеоролик о группировке в Топвизоре от уважаемого мною Михаила Шакина:
");">
А также видео от Александра Ожгибесова, которое, наверное, больше подходит продвинутым пользователям, хотя его польза для практической деятельности очевидна:
");">
Технические возможности в интерфейсе Topvisor
Итак, практически все действия по созданию семантического ядра разобраны. Теперь посмотрим, какие опции сервиса могут упростить нам выполнение задачи и внести необходимый комфорт при работе в интерфейсе. Обратим внимание на основные наиболее полезные фишки.
Естественно, что после получения полноценного ядра у вас образуется достаточно много групп. Чтобы было удобнее ими управлять, можно выделить нужные вам на этот момент и пометить их галочками, нажав на кнопку с изображением глаза:

В итоге на экране появятся лишь те, которые вы выберите, остальные будут просто скрыты из области видимости. Также есть возможность самыми разнообразными способами редактировать состав групп и перемещать сами блоки и отдельные ключевики в интерфейсе.
Вы добавляете сколь угодное число новых групп, каждый раз нажимая на плюс в центре серого прямоугольника. Тут же можно вписать и их название исходя из собственных предпочтений:

Обратите внимание, что слева от наименования группы находится кружок. Если он серого цвета, то данная группа отключена, то есть съем позиций по находящимся в ней запросам невозможен. Ежели кликнуть по кружку мышкой, то он примет зеленую окраску, что будет означать, что эта группа включена. Также возможно и обратное действие. Включить/отключить все блоки (группы) возможно с помощью переключателя в правом верхнем углу:

Идем дальше. Из созданного списка в любой группе можно отыскать нужный запрос, нажав на традиционный значок с изображением лупы. Щелчком по символу с тремя точками вызывается контекстное меню, в котором имеется практически весь основной функционал, необходимый для действий с данным конкретным блоком (можно проверить частоту входящих в него запросов, сохранить их в файл, копировать в другой проект либо в буфер обмена), вплоть до его удаления:

Есть возможность упорядочить все слова и словосочетания по алфавиту (с начала или с конца), по возрастанию или убыванию частоты или цены за клик:

Кроме того, если ввести ключевую фразу в нижнюю графу, которая присутствует в каждом блоке, и нажать на плюс, то данное словосочетание будет немедленно добавлено в группу. Ежели в ней собралось большое число ключей (более ста), то она разбивается на несколько пронумерованных страниц. Номер странички можно выбрать из появившегося меню в правом верхнем углу блока.
Обратимся еще раз к общему верхнему меню в инткрфейсе Топвизора. Иконка с корзиной дает возможность перейти к списку последних удаленных запросов и при необходимости восстановить какие-то из них:

В дополнение к выше сказанному данный сервис предлагает кроме отображения групп блоками еще и табличный режим , который станет постоянным, если число ключевиков перевалит за 5000 (в этом случае вывод блоков станет невозможным). Переключение между двумя способами происходит с помощью двух первых кнопок верхней панели:

В таком режиме интерфейса с имеющимися данными можно производить все возможные действия: удалять отдельные папки или группы, изменять их названия, добавлять новые, перемещать.
Акцентирую ваше внимание на том, что основные операции (проверка частотности, экспорт, установка тегов, назначение целевой ссылки, перемещение, удаление) можно осуществлять для любого количества запросов (просто напротив нужных поставьте галочку).
Если повнимательнее взглянуть на скриншот выше, то можно разглядеть практически готовую структуру сайта, где папки, являющиеся по сути рубриками, включают в себя группы (отдельные страницы или статьи), содержащие те ключевики, под которые и заточены странички.
Я, например, при использовании Топвизора для сбора семядра для своих проектов присваиваю папкам наименования рубрик, а группам — названия статей. Более того, если ваш веб-ресурс имеет более сложную структуру и в нем есть подрубрики, то и здесь система предусмотрительно позволяет создавать подпапки, которые могли бы им соответствовать.
И последнее, на что хотелось бы обратить внимание, это на возможность экспорта абсолютно всего ядра либо его части для дальнейшей работы с запросами в подходящем редакторе.
Как экспортировать отдельные ключи из конкретной группы, думаю, понятно, из скрина выше. А вот захват всех без исключения словосочетаний либо только ключевиков из нужных групп, возможно, некоторых поставит в тупик, а потому требует дополнительных разъяснений.
Чтобы экспортировать ядро целиком или же его часть, в левой части интерфейса Топвизора, где расположены группы, нужно нажать на слеш «/», обозначающий все папки и даже не входящие ни в одну из них запросы, а затем щелкнуть по слову «Все».
В итоге появится весь список групп и отдельных не связанных с ними ключевых слов. Вам надо лишь отметить нужные галочками (при экспорте всего ядра заполните все чекбоксы, отметив главный напротив опции «Группы»):

При этом можно копировать выбранные ПЗ как в другой проект, так и в буфер обмена в виде простого списка (его, например, можно потом легко вставить в обычный блокнот), правда, в этом случае наложено ограничение в 2000 слов.
Ну а главная ценность, конечно, это возможность экспортировать список ключевиков в виде файла формата CSV. Полученный документ можно открыть в программе Excel либо загрузить в интерфейс Гугл Таблиц для дальнейшей работы с ним. Вот как выглядит, например, скачанный мною документ из Топвизора в Google Sheets:

Как правильно проверить частотность поисковых запросов в Яндексе и очистить их от "мусора"? Какими операторами пользоваться для максимальной детализации ключевых слов? Как проверить базовую и точную частотность? Обо всем подробнее в данной статье.
Частотность - это количество показов поисковых запросов, набранных пользователями за определенный промежуток времени. В сервисе Яндекс WordStat данная статистика отображается за месяц. Большинство вебмастеров и владельцев сайтов знакомы с данным сервисом, однако, даже многие опытные специалисты до конца не понимают всю прикладную мощь данного инструмента .
Проверка частотности запросов в Яндексе для "чайников"
Для того, чтобы проверить базовую частотность, необходимо в поисковую строку WordStat вбить искомое ключевое слово. По-умолчанию статистика отображается по всем регионам и устройствам, однако, вы можете ее детализировать по десктопам, мобильным устройствам, только телефонам и только планшетам. Кроме того, сервис автоматически показывает похожие ключевые слова, предоставляет возможность посмотреть историю конкретных поисковых запросов за 2 года, а также детализировать запросы по регионам и городам. В данной статье мы рассмотрим только статистику по ключевым словам, всем устройствам и регионам WordStat.
Рассмотрим отображение базовой частотности WordStat по запросу "купить замОк".
Так, цифра 244 253 рядом c фразой «купить замок» обозначает число показов в месяц по всем запросам с ключевым словом «купить замок» : «купить замок зажигания», «купить замок на дверь», «где купить замок», «купить дверной замок» и т.п. Верхнее число показов - это сумма всех нижестоящих показов по всем отображенным словам .
Но как в таком случае проверить количество показов строго по запросу "купить замок" (дверной), убрав весь нетематических мусор: "детские зАмки", "замки зажигания", "замок автомобиля" и т.п. Для этого существуют операторы WordStat .
6 операторов для уточнения запросов
Операторы WordStat - это символы, которые помогут вам точнее сформулировать ключевую фразу для получения статистики. Их на данный момент существует 6.
| Оператор | Что делает | Пример ключевой фразы | Отображение статистики |
| ! | Жестко фиксирует слово (время, род, число, падеж) | купить замок в!москве |
|
| " " | Кавычки фиксируют количество слов в запросе | "купить замок" |
|
| + | Плюс фиксирует все частицы, предлоги и служебные слова в запросе. По-умолчанию они игнорируются | купить замок +на дверь |
|
| - | Минус удаляет все лишние слова из запроса | купить замок -автомобиля |
|
| Квадратные скобки фиксируют порядок слов в запросе | купить [замок дверной] |
|
|
| () и | | Пайп (вертикальная черта) и круглые скобки помогают при группировке сложных запросов | купить замок (недорого|дверной) |
|
Вся прелесть операторов заключается в том, что их можно использовать друг с другом. Совместное использование операторов для детализации запросов дает хорошему вебмастеру мощный seo-инструмент, который поможет не только собрать качественное семантическое ядро, но и вычленить из всей массы запросов именно нужную объективную статистику без семантического мусора .
Определяем точную частотность запроса: уровень Pro
Давайте попробуем комбинировать операторы, и посмотрим, что из этого получится. Для примера возьмем новый запрос "купить машину". Базовая частотность 1 533 200 показа в месяц по всем регионам и устройствам.

Это очень широкий запрос, который включает в себя множество других подзапросов из разных ниш, например, "купить стиральную машину", "купить машину ауди", "купить посудомоечную машину". Как мы можем детализировать данные запросы? Допустим, нас интересуют стиральные машины.

Если мы хотим посмотреть точное количество запросов по ключевой фразе "купить стиральную машину", начинаем использовать операторы: кавычки и восклицательный знак. Получается 9257 показов в месяц. Заметьте, что количество показов в таблице осталось базовым.

Чтобы посмотреть этот же запрос, но при этом жестко фиксировать последовательность слов в нем, исключив, например, запросы "стиральную машину купить", "машину стиральную купить", добавляем оператор . Точное количество показов именно по этой фразе с сохранением формы и последовательности слов - 8903.

Заметьте, если мы изменим последовательность слов в нашем регулярном выражении, то мы получим совершенно другой результат показов - всего 308. Это вполне логично и интуитивно понятно, что количество людей, которые ищут стиральную машину с большей вероятностью будут строить свой запрос именно со слова "купить".

Но если мы изменим словоформу данного запроса, то, опять же, получим совершенно новый результат.

Вот так, например, можно зафиксировать предлог в запросе и добавить геозависимое слово. Учтите, что на скриншоте идет сбор статистики по всем регионам WordStats, а не только по Москве.

Идем дальше. Предположим, что вы продаете только стиральные машины без сопутствующих товаров. Запрос "купить стиральную машину" включает в себя множество подзапросов, среди которых "купить раковину для стиральной машины", "купить тэн для стиральной машины", "купить шланг для стиральной машины". Чтобы собрать нужную семантику, у вас уйдет уйма времени на проверку каждого запроса с помощью операторов " " и!. В данном случае нам поможет оператор "минус".

Таким образом, вы очищаете "мусорные" запросы в статистике, фильтруя только релевантные ключевые слова для вашего бизнеса .
Проверка частотности: 80 lvl
Переходим к более сложным тонкостям сбора статистики по запросам из Яндекса .
Пример #1
Начнем с оператора " " и сформулируем одно правило его использования: если во фразе, заключенной в кавычки, присутствуют одинаковые предлоги или слова, то одно из них заменяется на существующее слово во вложенном запросе . Для примера рассмотрим запрос "автомобиль в кредит москва".

Если добавить в данное ключевое слово еще один предлог "в" перед словом "москва", то получим следующие данные.

Таким образом повторяющиеся предлоги "в" были объединены, и к запросам добавилось еще одно слово. Для разных запросов это слова "купить", "бу", "новый", "залог", подержанные". "оформить".
Этот прием - невероятный инструмент для информационный сайтов, основной целью которых является рост трафика. Он позволяет выбрать из тематики весь диапазон запросов, которые включают в себя заданное количество слов, например, все запросы по тематике из 5 слов. Как правило, очень расширенные запросы из 5-7 слов бывают менее конкурентными, соответственно привлечь трафик и занять высокие позиции по ним легче. А если эти запросы не уступают в показах высокочастотным запросам? Выборка наиболее высокочастотных и наименее конкурентных запросов позволит вам быстро добиться результата. Давайте рассмотрим пример.

В данном запросе мы просим WordStat показать диапазон запросов, который включает в себя 7 слов, обязательно содержащих слова "инструкция по применения". 5 слов "инструкция" объединяются, остается одно, 4 слова заменяются на новые вложенные запросы. Смотрим один из сотен вложенных запросов, частотность запроса из 7 слов - 8090 показов в месяц. Для сравнению запрос "купить автомобиль в москве" имеет 647 показов в месяц. Разрыв шаблона еще не произошел? Тогда идем дальше.

Пример #2
Сейчас пойдет в бой более сложный оператор () и |, с его помощью мы соберем пул запросов, из которого в дальнейшем сможем сделать теговые страницы. Возьмем для примера запрос "купить автомобиль bmw". Данную марку авто, ее серии могут искать по самым разным запросам: "купить машину бмв", "купить bmw икс 6", "купить автомобиль бмв 5" и т.п. Для того чтобы получить пул запросов без повторений, используем регулярное выражение:
Купить (автомобиль|машина) (бмв|bmw) -пробегом -фото -не -заводится -скачать -бу -какая
Добавим в него сразу ряд нерелевантных минус-слов, которые не подходят для нашего бизнеса. Получаем следующие данные, которые впоследствие проще структурировать.

Данная выборка поможет вам проще собрать данные для теговых страниц и кластеризации данных.
Обратите внимание , нельзя в одном выражении использовать операторы " " и () |. Логика работы одного оператора нарушает логику работы другого .
Пример #3
Данный пример подойдет для быстрой структуризации информационных сайтов или сбора тегов для интернет-магазинов. Для примера возьмем информационный сайт о рыболовстве и попробуем быстро получить основные направления и места рыбалки с помощью группировки запросов по предлогам. Сделаем это простым регулярным выражением:
Рыбалка (+с|+на) -игра -бесплатная -скачать -русские -охота
Минус-слова, конечно же, нужно добавить, но в данном случае это просто пример. Получаем вот такой результат:

Пример #4
Совместное использование операторов поможет вам разграничить похожие по написанию, но разные по смыслу запросы. Например, запрос "купить тур в москвУ" подразумевает экскурсионную поезду в Москву.

Запрос "купить тур в москвЕ" подразумевает учет геопозиции пользователя для покупки тура из Москвы.

Пример #5
Еще один пример регулярного выражения, которое поможет вам собрать запросы для теговых страниц или фильтров каталога в нише купальников.

Даже если данные примеры не относятся к вашей нише, надеемся они помогут вам улучшить свои навыки работы с WordStat. Если у вас возникли вопросы, вы нашли ошибки, либо хотите дополнить статью, пожалуйста, пишите в комментарии, мы с радостью ответим вам!
Очень важно убедиться, что запросы, по которым вы собрались продвигаться, вообще кто-то ищет. Если вы наберете «семантическое ядро», где все ключи будут с нулевой частотностью — то ваш сайт и будет нулём. Поэтому давайте не будем вола нагибать, а приступим.
Что такое частота ключевого слова
Очевидно, что различные запросы имеют разную популярность среди пользователей поисковых систем. Число ввода конкретного запроса в поисковик берется за один месяц. Таким образом, частота ключевых слов — это количество вводов запросов за месяц.
Вполне возможно, что даже тут есть запросы-пустышки
Для продвижения вашего сайта необходимо создавать оригинальный контент. Например, если вы пишете статьи, уникальность вашего текста должна быть, как правило, выше 90%. В теории, уникальный контент приносит высокий показатель посещаемости, состоящий в большей мере из переходов с Яндекса и Гугла. Однако в реальных условиях ранжирования написать уникальную статью — только половина успеха.
Поисковые системы обращают внимание не только на уникальность текста, но и на содержания в нем ключевых запросов, соответствующих тематике статьи или любого другого текстового контента. Правильное распределение ключевых слов в статье называют текстовой оптимизацией. Уникальная, но не оптимизированная статья, содержащие неопределенные запросы, может и вовсе не привлечь на сайт посетителей. Такая ситуация будет означать зря потраченные время и ресурсы на создание контента.
Для оптимизаторов, частотность это критерий по выбору того или иного запроса для его использования в тексте. В зависимости от частотности, на высокочастотные (ВЧ), среднечастотные (СЧ) и низкочастотные (НЧ) запросы. При оптимизации статьи, в первую очередь, обращают внимание на ВЧ и СЧ запросы. Однако с каждым годом продвижение новых сайтов становится все затруднительным, а оптимизация все тоньше. Сейчас считается, что использование НЧ ключей также может принести некоторый объем трафика.
Как проверить частотность запроса
Частотность ключевых слов можно узнать с помощью соответствующих сервисов поисковых систем, а также специальных программ по составлению семантического ядра. Поисковики предоставляют свои сервисы с расчетом подбора запросов для контекстной рекламы.
Wordstat (Яндекс)
Wordstat — cервис Яндекса по определению статистики ключевых запросов. Вордстат использует большинство оптимизаторов не только в целях составления коммерческих запросов под рекламу, но и для добычи ключевых слов в рамках обычной текстовой оптимизации. У Вордстата выделяют три вида частотностей:
- Частотность WS — базовая частотность запроса в Вордстате.
- Частотность «» WS — частотность по точному вводу запроса. Например, статистика по запросу [«автомобиль»] будет соответствовать запросу [автомобиль] без добавлений других слов.
- Частотность «!» WS — частотность по точному вводу каждого слова в запросе, исключая склонения и т.п. Запрос [!китайский] означает, что будет выдана статистика по слову [китайский] без возможных склонений (китайская, китайское).
По запросу [автомобиль] текущая частотность превышает десять миллионов показов. Однако базовый показатель предполагает добавление всевозможных слов к ключевому слову, по которым будет ранжироваться статья.

Если заключить запрос в кавычки, то статистика сократится с десяти миллионов до 28 тысяч. Для оптимизатора может оказаться полезной правая колонка с похожими запросами, которые дополняют семантический сбор.

Вкладка «По словам» означает, что статистика приводится по общей сумме показов введенного запроса. На вкладке «по регионам» отображается статистика показов в разных регионах страны. А на «Истории запросов» можно отследить по графике изменение частотности запроса в течении месяца или недели, а также статистику по по запросам через ПК или мобильные устройства.
Сервис Google AdWords сам по себе более заточен под контекстную рекламу, нежели Вордстат. В разделе «Инструменты» можно подобрать необходимые ключи под нужный запрос. В колонке «Таргетинг» задается нужный регион показов и язык. Также можно указывать минус-слова.

В отличии от Вордстата, где указывается статистика за месяц, в AdWords можно выбирать месячный диапазон показов в колонке «Диапазон дат». Недостатком является усредненный число результатов. Сама статистика разделена на два блока:
- Ключевые слова — аналог частотности «» Вордстата;
- Ключевые слова (по релевантности) — аналог базовой частотности и похожих запросов WS.

Плюсами являются присутствие уровня конкурентности, а также возможность скачать подобранные слова в CSV-файл или на Гугл Диск.
Помимо AdWords, Гугл имеет еще один инструмент по анализу запросов под названием Google Trends . Данный сервис оценивает популярность введенного запроса на определенный период времени и представляет статистику в виде графика. Можно сравнивать несколько ключевых запросов между собой. Также отображается статистика по регионам.

Для графика используются не точные числа, а относительные, основанные в том числе на релевантных запросах.
Mail.ru
Mail.ru также имеет в сервисе для вебмастеров инструмент по статистике поисковых запросов. Помимо общих показов, в таблице представлены распределение запросов по полу и возрасту пользователей.

Не секрет, что Mail сотрудничает с Яндексом, так как поисковик размещает рекламу Яндекса.
Rambler
Rambler с каждым годом теряет свою популярность, однако их Wordstat может оказаться весьма полезным. Дело в том, что статистика запросов в Яндексе и Гугле не всегда может отображать реальное положение вещей. Многие компании могут вводить «в холостую» коммерческие запросы в целях слежки за конкурентами, т.е. для анализа ТОПа, тайтлов и т.д.

По причине низкой популярности Рамблера, статистика их Вордстата обладает меньшей заспамленностью и может внести некоторую ясность для оптимизаторов. В общем, в качестве дополнительного инструмента вполне сгодится.
Как проверить массово частотность запросов
Большинство оптимизаторов выбирают для сбора и анализа семантического ядра такие программы, как Key Collector или Slovoeb. Также существуют онлайн-сервисы по определению частотностей.
Key Collector
Получить необходимые ключи для семантического ядра и массово проверить их частотность можно при помощи десктопной программы Key Collector . Открываем Вордстат, в поле заносим основные ключи с новой строки по вашей тематике и нажимаем «Начать сбор».

В настройках можно задавать требуемый регион для сбора, а также стоп-слова. После того как ключи соберутся, определяем частотности через Директ.

В итоге у вас будет таблица с ключами и частотой показов. Сразу удаляем все ключи, у которых точная частотность «!» равна нулю. Для этого делаем фильтрацию в колонке «Частотность!». Кликаем на синюю иконку. Появится окно с фильтром. Выбираем «больше или равно» > «1» и жмем «Применить».

Для получения большего списка ключей можно собрать поисковые подсказки с Яндекса. Делаем новую группу (окно справа).
Также убедитесь, что включена галка «Собирать только ТОП подсказок без перебора…». Теперь кликаем на созданную группу – откроется новая пустая вкладка. Жмем иконку сбора поисковых подсказок.
После сбора фраз делаем то же самое, что и при парсинге Вордстата: снимаем частотности, убираем неподходящие по смыслу фразы и фразы, где частотность «!» равна нулю.
Аналогично с помощью Key Collector можно собрать ключи и частотности с Гугла.
Rush Analytics
Сервис Rush Analytics является онлайн-альтернативой Key Collector. Плюсом инструмента по сбору ключей является отсутствие необходимости использовать прокси, антикапчу и т.п.
Для сбора частотности с Вордстата, необходимо перейти на вкладку «Сбор частотности» и поставить галочку напротив !ключевое слово , то есть точной частотности. Далее заносим ключевые слова. После того, как сервис посчитает затраты, нажимаем «Создать новый проект».
Результаты можно сохранить в Excel-файл.
Перед тем, как что-то делать в интернете: создавать сайт, настраивать рекламную компанию, писать статью или книгу, надо посмотреть, что вообще ищут люди, чем интересуются, что вводят в поисковой строке.
Поисковые запросы (ключевые фразы и слова) чаще всего собирают в двух случаях:
- Перед созданием сайта. В этом случае нужно собрать максимум ключевых слов, чтобы охватить всю вашу сферу. После сбора, поисковые запросы анализируются и на основании этого принимается решение о структуре сайта.
- Для настройки контекстной рекламы. Для рекламы выбирают не все, а только слова, по которым можно определить интерес к товару или услуге, желательно активный интерес выраженный словами «купить», «цена», «заказать» и т.п.
Если вы собираетесь настраивать контекстную рекламу, то .
А ниже мы рассмотрим, как собрать статистику поисковых запросов в популярных поисковых системах, а так же небольшие секреты, как это сделать лучше.
Как посмотреть статистику запросов Яндекс
У поисковой системы Яндекс есть специальный сервис «Подбор слов», находящийся по адресу http://wordstat.yandex.ru/ . Пользоваться им очень просто: вводим любые слова и обычно, кроме статистики по этим словам, также видим что искали вместе с этими словами.
Очень важно понимать, что статистика по более коротким запросам, включает в себя статистику всех подробных запросов с этими словами. Например, на скриншоте запрос «статистика запросов» включает в себя запрос «статистика запросов яндекс» и все остальные запросы ниже.
В правой колонке отображаются запросы, которые искали люди, искавшие введенный вами запрос. Откуда берется эта информация? Это запросы, которые были введены до вашего запроса или сразу после него.
Чтобы посмотреть точное количество запросов по фразе, надо ввести ее в кавычках «фраза». Так, конкретно запрос «статистика запросов» искали 5047 раз.

Как посмотреть статистику поисковых запросов Google
С недавних пор для России стал доступен инструмент Гугл Тренды, он находится по адресу http://www.google.com/trends/ . Он выводит популярные в последнее время поисковые запросы. Вы можете ввести любой свой запрос, чтобы оценить его популярность.
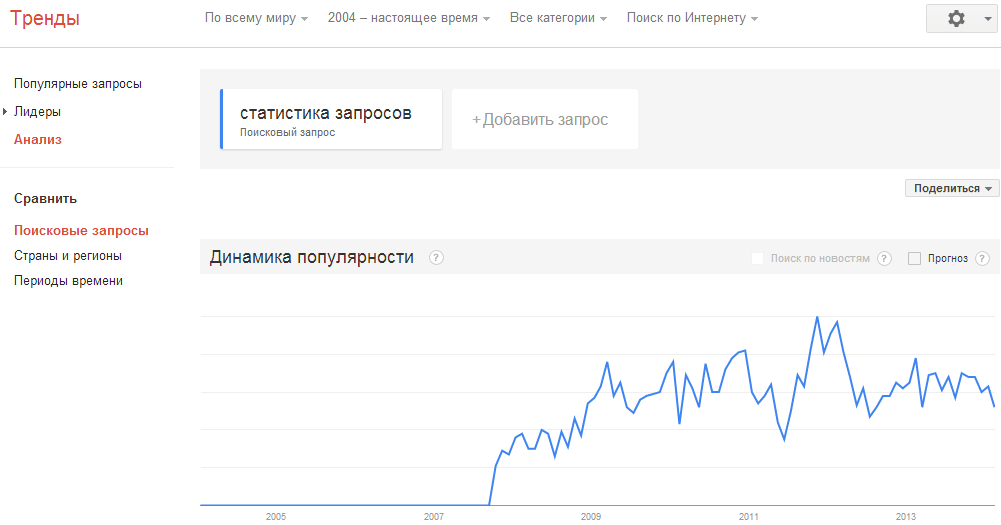
Кроме частоты запросов, Google покажет популярность по регионам и схожие запросы.
Второй способ посмотреть частоту поисковых запросов Гугл — это использовать сервис для рекламодателей adwords.google.ru. Для этого нужно зарегистрироваться как рекламодатель. В меню «инструменты» нужно выбрать «Планировщик ключевых слов» и дальше «Получить статистику запросов».

В планировщике, кроме статистики, вы узнаете уровень конкуренции рекламодателей по этому запросу и даже примерную стоимость клика, если решите тоже рекламироваться. К слову, стоимость обычно завышена.
Статистика поисковых запросов Mail.ru
Майл.ру обновил инструмент показывающий статистику поисковых запросов http://webmaster.mail.ru/querystat . Главная фишка сервиса — это распределение запросов по полу и возрасту.
Можно предположить, что сервис подбора слов Яндекса также учитывает запросы из Mail, т.к. в данный момент поисковая система Mail.ru показывает рекламу Яндекса, а сервис в основном рассчитан на рекламодателей. А раньше кстати, в Mail.ru показывалась реклама Google.
Кроме того, можно пользоваться такой хитростью. Примерное распределение аудитории между поисковиками такое: Яндекс — 60%, Гугл — 30%, Mail — 10%. Конечно, в зависимости от аудитории, соотношение может меняться. (Например, программисты могут отдавать предпочтение Google.)
Тогда можно посмотреть статистику в Яндекс и делить на 6. Получаем приблизительное количество поисковых запросов в Mail.ru
Кстати, точное распределение аудитории между поисковиками на Февраль 2014 года можно увидеть на скриншоте снизу:

Статистика запросов Rambler
Из графика выше уже можно заметить, что поисковая система Рамблер охватывает всего 1% аудитории интернета. Но тем не менее, у них есть свой сервис статистики ключевых слов. Он находится по адресу: http://adstat.rambler.ru/wrds/

Принцип такой же, как и в остальных сервисах.
Поисковой системой Бинг пользуется еще меньше наших соотечественников. А чтобы посмотреть статистику ключевых слов, придется зарегистрироваться как рекламодатель и разбираться в инструкциях на английском языке.
Сделать это можно по адресу bingads.microsoft.com, а статистику запросов можно будет посмотреть на этапе создания рекламной компании:

Статистика запросов Yahoo
В этой системе как и в предыдущей, вам нужно зарегистрироваться как рекламодатель. Смотреть статистику поисковых запросов надо здесь http://advertising.yahoo.com/
Как посмотреть поисковые запросы Youtube
Youtube тоже имеет свою статистику поисковых запросов, который называется «Инструмент подсказки ключевых слов». В основном он предназначен для рекламодателей, но ведь его можно использовать, чтобы прописывать у своего видео подходящие ключевые слова.
И выглядит примерно вот так:

Итог.
Мы рассмотрели все популярные системы подбора поисковых запросов. Надеюсь, этот обзор пригодится вам для написания статей, создания сайтов или настройки рекламы. Если у вас остались вопросы — задавайте их в комментариях.
Здравствуйте, уважаемые читатели!
Появилась идея объединить все статьи, касающиеся темы частотности поисковых запросов. И вот я спешу ее воплотить.
Сегодня мы поговорим об анализе частотности поисковых запросов, объединив все знания, накопленные в предыдущих текстах.
Частотность запросов
Прежде всего, снова определимся, как мы будем группировать запросы. Уже ни для кого не секрет, что выделяются низкочастотники (НЧ), среднечастотники (СЧ) и высокочастотники (ВЧ). Но как определить, к какой группе отнести запрос? Ранее я предложил такую схему:
- НЧ – до 700 запросов в месяц;
- СЧ – до 2000 запросов в месяц;
- ВЧ – все остальные.
Эта схема и сейчас справедлива, но применима она для сео-тематики.
В действительности же большинство сеошников руководствуются следующей схемой:
- до 1000 – низкочастотные;
- 1 – 10 тыс. – среднечастотники;
- свыше 10 тыс. – высокочастотники.
Эта формула также верна, но она считается общей. Если же вы работаете в конкурентных тематиках, где пробиться в ТОП поисковиков крайне сложно, то эти цифры снижаются.
Теперь вы понимаете, что частотность лучше определять в зависимости от того, к какой тематике принадлежит ваш ресурс.
НЧ, СЧ и ВЧ
Я думаю, не стоит подробно описывать каждый тип запросов, его особенности и нюансы. Все это уже было достаточно подробно изложено в предыдущих статьях, вам просто нужно их прочитать:
Эта тема также неоднократно поднималась в предыдущих статьях (например, в статье ), но, как говорится, повторение – мать учения.

Итак, есть три сервиса, которые подходят для анализа частотности запросов:
- Гугл.Адвордс
- Рамблер.Адстат
Самый точный – Яндекс.Вордстат, т.к. он охватывает более 50% русскоязычной аудитории (через поисковики Яндекс, Мейл и т.д.), соответственно и цифры здесь самые близкие к истине.
На втором месте – Адвордс от Гугла. Область охвата рунета – около 30%, поэтому точность определения запросов тут ниже. Но все же этот сервис не стоит сбрасывать со счетов.
Хуже всего определяет частотность запросов Рамблер.Адстат, статистика которого покрывает около 10% рунета. Про Гугл.Адвордс и Рамблер.Адстат читайте в статье « ». Про вордстат поговорим подробнее.
Вордстат
Перейти на этот сервис можно по этой ссылке .
Введя поисковый запрос, вы получите картину его частотности. Не забывайте использовать операторы вордстата:
- Если введен в окошко запрос (окна пвх), то будет посчитано, сколько раз был вообще набран этот запрос в яндексе (окна пвх, стоимость окн пвх, купить окна пвх, окна пвх в Москве и т.д.)
- Если запрос введен в кавычках («окна пвх»), то будет посчитано, сколько раз использовался этот запрос и его словоформы (окна пвх, окон пвх, окнами пвх, окнам пвх и т.д.)
- Если ввести запрос в кавычках и с восклицательным знаком перед каждым словом («!окна!пвх»), то будет посчитано, сколько раз вводился конкретно данный запрос.
Поэтому если вам нужно знать точное количество запросов, то используйте кавычки и восклицательные знаки.

Определяя частотность, не забывайте, что низкочастотный запрос не всегда бывает низко конкурентным, а высокочастотный – высоко конкурентным. Поэтому будьте внимательны, старайтесь определять и частотность и конкурентность запроса.
Похожие статьи
-
Личный кабинет сумма телеком
Основные преимущества работы провайдера Сумтел в Воронеже: Широкая линейка тарифов, позволяющая каждому космополиту определиться с выбором требуемого и удобного именно для него пакета предложений. Система лояльности, заключающая в...
-
Какой скорости интернета достаточно?
В России очень хороший и, что не менее важно, доступный домашний интернет. Серьёзно! В деревнях и совсем глубокой провинции дела, конечно, похуже, но возьмите любой, даже небольшой город в европейской части страны и посмотрите тарифы. За...
-
Как цитировать, чтобы пройти антиплагиат
До 2007 года российские студенты, выполняя дипломные работы, пользовались любыми источниками и не боялись, что их обвинят в заимствовании чужих текстов. Сейчас все поменялась, и абсолютно все письменные работы проверяются на антиплагиате....
-
Программы для просмотра ТВ через интернет: лучшие приложения для стационарных и мобильных систем
Подключение телеприемника к интернету дает множество преимуществ и удобств: возможность смотреть ролики на YouTube, а не только телеканалы, подписываться на сервисы потокового мультимедиа и др. В рамках статьи мы опишем все варианты, как...
-
Как настроить бесплатные каналы на Smart TV
Приветствую всех на страницах блога сайт. Наконец добрался я до своего блога и решил написать о том, как настроить и подключить телевизор Самсунг к интернету? Думаю многим это будет интересно. И сразу же перейдем к делу. Подключить...
-
Три способа подключения «Мобильного банка» от Сбербанка
Мобильный банк — такой же важный инструмент управления своими деньгами, как и сервис Сбербанк онлайн. Тем более, второй без первого практически не работает! Пакет «Эконом» берет с клиента 15 рублей за проверку последней операции на карте и...